- addBackgroundImage
- addFooter
- addHeader
- addLineNumbering
- addMacroFromDoc
- addPageBorders
- addProperties
- addSection
- createCharacterStyle
- createListStyle
- createParagraphStyle
- docxSettings
- importHeadersAndFooters
- importListStyle
- importStyles
- modifyPageLayout
- parseStyles
- removeFooters
- removeHeaders
- setBackgroundColor
- setDefaultFont
- setDocumentDefaultStyles
- setEncodeUTF8
- setLanguage
- setMarkAsFinal
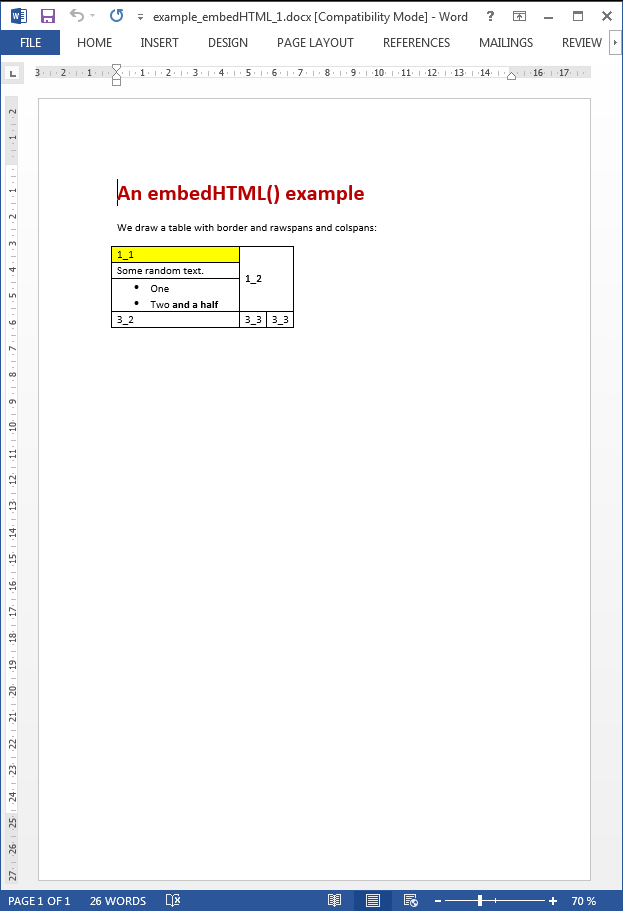
pdx:embedHTML
Inserts HTML content into the Word document.
Description
Element definition
This element allows the insertion of HTML into the current Word document.
Practically all HTML tags and CSS styles are supported.
This element transforms HTML directly into WordML and it is compatible with OpenOffice and PDF conversion.
You may find a more detailed explanation of this useful element in the HTML to Word section of the API documentation.
Attributes and sub-elements
html
The html code to be translated into WordML: it could be a string or the path to a file.
options
| key | Description |
|---|---|
| addDefaultStyles | True as default, if false prevents adding default styles when strictWordStyles is false. |
| baseURL | The base URL used to complete the relative paths of links and images. |
| customListStyles | If true checks if there is a custom list style with that name and uses it. |
| downloadImages | If true inserts the images into the docx document, otherwise just links them as an external source. |
| filter | Only renders the filtered contents. It could be an string denoting an id ('#myId'), a class ('.myClass'), a HTML tag or a valid XPath expression ('//expression'). |
| isFile | True for files and false for strings. |
| parseAnchors | If true parses the anchors included in the HTML code. |
| parseDivsAsPs | If true parses the div elements as paragraphs. |
| parseFloats | If true preserves the floating properties of images and tables. |
| strictWordStyles | If true ignores all CSS styles and uses the styles set via the wordStyles option (see next). |
| useHTMLExtended | If true allows using HTML Extended tags. Disable as default. Only available in Premium licenses. |
| wordStyles | One may associate different Word styles to HTML classes, ids or tags. |